

Coordinated movement in humans doesn’t come solely from our conscious planning centers. When we decide to walk across a room or reach for a cup, it’s not the prefrontal cortex (the brain’s planner) that figures out how to fire each muscle. Instead, that job falls to the motor cortex, a specialized set of brain regions that translate high-level intent into the precise, real-time muscle activations needed to keep us balanced and moving fluidly. This division of labor allows the brain’s planning areas to focus on goals and strategy while the motor cortex handles the fast, reactive work of motion execution.
Humanoid robots face the same fundamental challenge. High-level planners can choose goals and trajectories, but they can’t directly manage the millisecond-scale joint torques and balance adjustments needed to execute those plans in the real world. That’s where a whole-body controller (WBC) comes in. Functionally similar to the human motor cortex, a WBC serves as the robot’s execution layer, bridging the gap between low-level coordinated motor signals and abstract commands, such as root velocities, joint targets, or keypoint trajectories. Operating in real time, it must also handle unexpected disturbances and the inherent uncertainty of the physical world, ensuring the robot stays stable and responsive.
The motor-cortex analogy suggests that humanoid AI should include an explicit WBC. But analogy alone isn’t enough. In an era where the “bitter lesson” often favors end-to-end architectures with minimal hand-designed structure, it’s worth asking: Do we actually need explicit WBCs, or is an end-to-end architecture all we need?
Why an explicit WBC?
Over the past 18 months, we’ve seen a surge of humanoid demonstrations and papers from both academia and industry including walking, running, dancing, martial arts, vacuuming, grocery handling, package sorting, and more. These systems use a variety of AI architectures, many involving machine learning. So, do these systems actually include explicit whole-body controllers?
In most cases, the answer is yes. Consider the very common class of demonstrations where a humanoid’s motion is dictated by a teleoperation interface or retargeted human motion from mocap or video. In these setups, the entire AI stack is effectively a WBC: its only job is to generate the low-level motor commands that stably and accurately track the target motions.
Another class of demonstrations is autonomous task execution, such as package sorting or pick-and-place. Typically, these systems are trained from human teleoperation data, which depends on a WBC to produce stable robot motion from teleop input during data collection. Thus, a WBC is at least involved in the, often extensive, data collection. But what about the test-time execution architectures?
The actual test-time architecture may or may not include an explicit WBC. For example, the HumanPlus hierarchical architecture includes an explicit frozen WBC at the lowest level. The WBC is first trained (see below for how), then used to collect demonstrations. That demonstration data is used to train a higher-level model to replace the human teleoperator by autonomously generating motions that are fed to the WBC.
An alternative architecture, such as Figure’s Helix, is an end-to-end, two-level hierarchy where a high-level vision-language model operates at a slow control rate while a low-level policy produces motor commands at a fast rate. In these cases, the low-level policy is essentially a WBC, though it’s trained jointly with the rest of the system rather than as a separate, reusable module.
The appeal of the end-to-end approach is that, with enough diverse teleop data, the low-level policy might generalize broadly without extra engineering. But there are risks: policies trained only on demonstrations may lack the stability and disturbance rejection of a deliberately trained and tested WBC. For example, how will such a policy learn to recover from unexpected pushes if those events aren’t in the dataset? And if we need a robust WBC to provide those examples during teleop anyway, why not keep that WBC in the final stack?
For now, my view is that explicitly trained WBCs remain valuable—both as robust execution layers and as independently testable components that can be improved without retraining the entire humanoid AI. But we are in early days and practical experience will ultimately guide us.
Why learn WBCs?
Fixed-base and wheeled robots are fundamentally stable and low-level control can often rely on standard, model-based methods. A high-level planner specifies an end-effector trajectory, and a simple low-level controller (e.g. inverse kinematics + PD) turns it into smooth joint torques—no need to worry about balance. In contrast, humanoids are fundamentally unstable bipeds. Their low-level controller must actively manage balance and whole-body coordination just to stand still, let alone walk or manipulate objects.
There’s been a long history of model-based whole-body control for humanoids, built around techniques like inverse dynamics, reduced-order models, and model predictive control. While these methods have produced impressive demonstrations—most famously from companies like Boston Dynamics with their marvelously engineered systems—they haven’t delivered comparable performance in the broader research community. Outside of a handful of engineering-heavy efforts, model-based control hasn’t produced the level of robustness, agility, or ease of deployment that we’re seeing today with learned controllers.
This is why we are seeing an increasing trend toward learned whole-body controllers—typically trained via reinforcement learning in simulation and then transferred to real hardware. Learned WBCs can internalize the complex dynamics, balance strategies, and fast reactive behaviors needed for fluid motion, traits that are difficult to encode explicitly. The result is a level of performance and generality that traditional approaches have struggled to match without massive engineering investment.
It’s also worth recognizing another reason learning-based approaches are gaining ground over model-based ones: the barrier to entry is lower. Building model-based systems demands deep expertise in control theory, dynamics modelling, and optimization, while learning-based pipelines can often be assembled without that background. In my view, this doesn’t make the traditional skill set irrelevant, since understanding those foundations is still invaluable for shaping intuition and diagnosing problems. However, I doubt humanoid robotics will ultimately be “solved” through hand-crafted models and controllers. The computational complexity of fully functional humanoids likely exceeds what we can capture analytically, at least in the near term. Our real challenge isn’t deriving the perfect equations, but learning how to most effectively train systems that can master these complexities on their own.

An Inventory of RL-Trained WBCs
Over the past 18 months, research on sim-to-real learned whole-body controllers has surged. These systems are being trained entirely in simulation and transferred to real humanoid robots. This approach now feels less like an experiment and more like the direction the WBC sub-field is headed.
To help make sense of this fast-growing space, I’ve compiled an inventory of learned WBCs, classifying each by its functionality, architecture, and training strategy. The full compilation is available in a publicly readable spreadsheet, which I plan to expand as new approaches emerge. I welcome suggestions, additions, and corrections from the community.
To keep the scope focused, each WBC in the inventory meets five criteria:
Demonstrated on a real humanoid robot (not just simulation).
Documented in a reasonably detailed technical paper.
Trained via deep learning, typically combining reinforcement and supervised learning.
Controls all actuated joints, rather than delegating parts of the body to traditional model-based controllers (with the exception of hands).
Functions as a general motion interface, rather than being tuned for a single skill or task.
Of the 18 systems, 14 support both locomotion and some form of manipulation (loco-manipulation): Hover; MHC; R2S2; GMT; ExBody2; TWIST; HST (HumanPlus); ExBody; FALCON; ARMOR; VMP; CLONE; OmniH20.
The remaining 4 focus exclusively on locomotion: H20; SaW; UCB-Loco; VideoMimic; ETH-Loco. These still qualify as humanoid WBCs, since even “pure” locomotion requires coordinated whole-body motion, including torso and arm adjustments for stability.
Table 1 presents a coarser view of the spreadsheet data that covers the key aspects of WBCs discussed in this post. In the following sections, I’ll walk you through this table from top to bottom. My goal is to provide both a light tutorial on how these RL-trained WBCs are built and operate, and to highlight some trends and gaps that emerge from the current landscape.
Robots Platforms
First, let’s see what the inventory reveals about the robot platforms. The trend is clear: 12 of the 18 controllers run on Unitree hardware: 6 on the G1, 5 on the H1, and 1 on both. The next most common platform is Agility Robotics’ Digit V3, which appears in 3 entries.
Unitree’s dominance in this list is no mystery. Until the H1 became available, researchers had few options for acquiring a humanoid robot without deep corporate ties or DIY engineering. Most commercial humanoid developers either weren’t selling to academics or were focused on tightly controlled pilot programs. By contrast, Unitree’s humanoids are orderable, relatively affordable, and functional enough for serious research. While the G1’s list price has been as low as $16K, a fully equipped setup might land in the $40–50K range, which is roughly the same scale as a modest GPU server investment for many labs.
Just as importantly, the G1 and H1 are simulation-friendly. Both feature simple designs and widely available physics models, making them easy to integrate into engines like MuJoCo and NVIDIA’s Isaac for sim-to-real training. This combination of affordability and digital accessibility has lowered the barriers to humanoid robotics research more than ever before.
The broader trend is clear: as more low-cost humanoids enter the market, the pace of progress in learned whole-body control and higher-level humanoid AI will only accelerate. But with that accessibility will come a flood of noisy, uneven-quality work, much as we’ve seen across AI at large. Sorting the signal from the noise in the arXiv stream could become a full-time job.
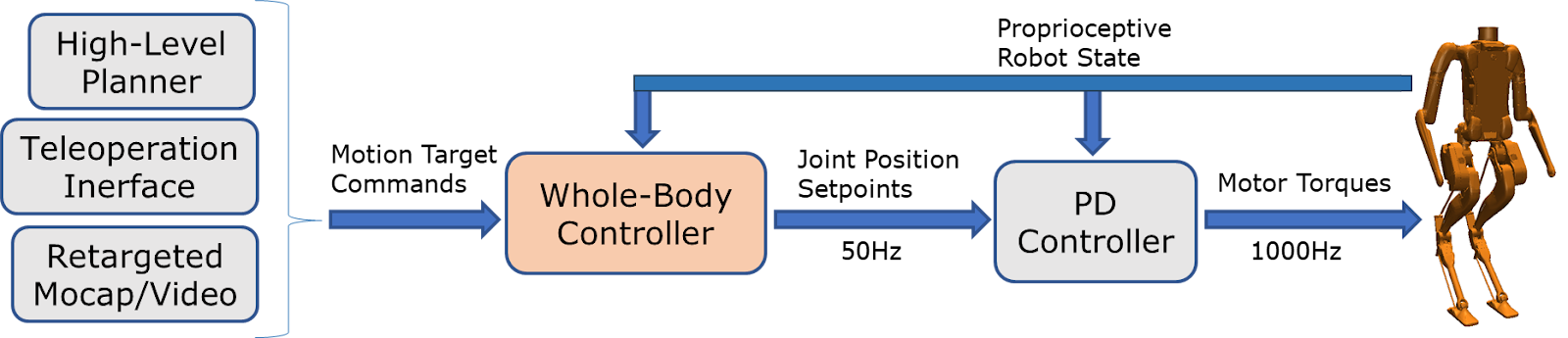
WBC API: Inputs/Outputs
A WBC provides an API between higher-level motion commands and the robot’s low-level motor control. The figure shows how this WBC API is typically placed within the overall robot control stack. What does the inventory reveal about the input and output choices for this API?
WBC Output
The inventory reveals that every WBC outputs joint position setpoints for the robot’s actuated joints (i.e. target motor positions), always at a 50 Hz control rate when specified.
These setpoints don’t drive the motors directly. Instead, they feed into a proportional-derivative (PD) controller that runs at ~1000 Hz, converting the target positions into motor torques. The PD gains are hand-tuned and remain fixed, providing a fast and predictable layer for torque-level control.
Why this two-stage approach rather than having the WBC output torques directly? Part of it is continuity with prior work—this structure is frequently used in physics-based character animation and early successes of learned legged locomotion. But there are practical engineering reasons as well:
Hardware constraints: Smooth, contact-reactive motor control typically needs ~1000 Hz actuation. Running a neural-network WBC at that rate is challenging given onboard compute limits. Using the PD layer as a buffer allows the WBC to operate at 50 Hz, where more computation is possible.
Reinforcement learning efficiency: All WBCs in the inventory are trained at least in part with RL, and reducing the decision rate from 1000 Hz to 50 Hz cuts the number of decisions per episode by 20×. This not only reduces the number of neural network calls during training, but also shortens the RL horizon, simplifying credit assignment and speeding up learning. The PD layer plays a second, subtler role here: it acts like a shock absorber, smoothing out the noisy, contact-rich dynamics of the real world before they reach the WBC. By buffering the WBC from the full brunt of these disturbances, the PD controller makes the RL problem easier to solve.
This pattern of producing joint setpoints at a moderate rate, stabilized by a high-rate PD layer, has become the default template for learned humanoid WBCs. It remains to be seen if this choice will reveal limitations, especially in applications requiring precise force control for manipulation.
Input 1: Robot State
Every WBC takes some representation of the robot’s kinematic and dynamic state as input, but the exact signals vary. At a minimum, all 18 controllers rely on proprioceptive data from the robot’s joint encoders and inertial measurement unit (IMU). Specifically, every WBC uses:
Joint angular positions and velocities
The root gravity vector (or equivalently, the robot’s roll and pitch)
Root angular velocity
These quantities can be reliably estimated from the onboard encoders and IMU.
However, just providing the current state isn’t enough to fully capture the robot’s dynamics. Information about accelerations or higher-order motion can’t be inferred from a single snapshot, so WBCs use a few different strategies to recover it:
Proprioceptive history: Many controllers include a window of recent proprioceptive states in their inputs, giving the policy temporal context to infer accelerations. The history length varies by implementation ranging from 25 to just 1 (no history).
Action history: Several WBCs also include a history of their own recent outputs/actions (joint setpoints), which can help the policy disambiguate dynamic effects like momentum or actuator lag. The history windows range from 25 to 0 (no actions). 13 of the WBCs include both proprioception and actions.
Internal memory: Two systems use a WBC architecture with built-in recurrence (e.g., an LSTM), allowing it to retain a compressed internal representation of the history rather than relying entirely on explicit history windows.
Overall, the inventory shows a wide range of strategies for capturing the robot’s dynamic state. Only one WBC relies solely on the current proprioceptive state with no action or temporal context (though this could reflect an incomplete description in the paper). The other 17 all incorporate state history, action history, or both, with 13 using both. This suggests that some form of temporal context is generally important for capturing the robot’s dynamics, but the specific configuration—history length, action inclusion, or reliance on recurrence—tends to be treated as a tunable hyperparameter, chosen pragmatically based on what each team found to work adequately.
A smaller subset (4 WBCs) also include linear root velocity as part of the state. However, estimating linear velocity for legged robots from IMU data is notoriously difficult and noisy. In real-world evaluations, these WBCs rely on external motion tracking systems to provide this velocity estimate—a significant limitation for practical deployment.
Two locomotion-only WBCs go further, incorporating a local terrain height map to help adapt their gait to rough terrain. In one case, the height map is derived from prior modeling with motion capture localization; in the other, from online reconstruction using LIDAR or depth sensing. The remaining WBCs focus on relatively flat terrain, where blind walking is sufficient.
In fact, 16 of the 18 WBCs are “blind” to the external world, relying entirely on proprioception and delegating any vision or environment reasoning to higher-level control. This raises an important design question going forward: how much exteroceptive input should a WBC process, and for what purpose?
It seems likely that the answer will not be zero. For example, should a high-level planner micromanage foot placement when climbing stairs, or should the WBC handle basic, “common-sense” step selection if given a height map? Should all collision avoidance—even for small, local obstacles—be pushed to the high-level planner, or should the WBC have enough spatial awareness to make local, reactive adjustments? The challenge will be to give WBCs just enough exteroception to handle local, reactive decisions while keeping their reasoning shallow, leaving more abstract planning to the layers above.
Input 2: Target Motion Commands
From the WBC API perspective, the most important input category is the target motion command, which specifies the higher-level intent the WBC must realize. These commands can be expressed at very different levels of abstraction, and that choice determines not only what the WBC must compute internally but also what modalities can drive it.
For example, a controller driven by VR-based teleoperation benefits from a simple interface: end-effector targets and base velocities, with the WBC filling in the rest of the body’s motion. By contrast, when the goal is to reproduce human motion from mocap or video, the command input must be far richer—often specifying full-body joint angles or key body positions to faithfully capture the demonstration. The abstraction level reflects both the upstream source (teleop, planner, motion retargeting) and the intended role of the WBC, whether as a task-oriented execution layer or a faithful motion reproducer.
Across the 18 controllers in the inventory, four primary command modalities emerge (with many WBCs supporting more than one):
Root velocity target (9 WBCs): This modality supports joystick-like locomotion control, where the robot is given target linear and angular velocities for its root. This abstraction is valuable because it relieves higher-level controllers from generating gaits, managing balance, or full-body poses leaving those details entirely to the WBC.
Root pose target (11 WBCs): Most loco-manipulation controllers allow direct specification of the base orientation or tilt, which is essential for tasks like leaning to reach objects or adjusting stance during manipulation.
Whole-body pose targets (8 WBCs): These controllers can track full-body configurations, expressed either as body keypoints (pelvis, feet, hands, head) or as full joint angles. Keypoints are especially convenient for mocap and video inputs, which naturally produce them. However, keypoints can be converted to joint positions via inverse kinematics for WBCs that accept only joint positions, adding computational cost upstream.
Upper-body pose or end-effector targets (6 WBCs): Among controllers that don’t track full-body poses, most still support upper-body pose or hand target inputs (via keypoints or joints). Three combine this with root velocity control for locomotion, while the others implicitly generate locomotion as needed to achieve the upper-body targets. From the perspective of providing a high-level loco-manipulation interface, supporting the combination of upper-body pose + root velocity may be a sweet spot in the practical application space.
Beyond these modalities, multi-modality is an important property. While 15 WBCs use a fixed command input format, three controllers allow the command interface to vary: the same WBC can be driven by simple root velocity commands for navigation, or by detailed keypoint or joint targets for full-body precision. By contrast, several controllers require both whole-body pose targets and root velocity at all times, which limits their use as a pure “joystick” abstraction because upstream systems must constantly generate full-body targets. From an API perspective, the multi-modal flexibility is appealing, as it allows a single WBC to span roles—from coarse executor to detailed reproducer—without retraining or swapping between different WBCs.
Regardless of modality, all WBCs operate as dense, high-rate trackers, consuming target motion inputs at about 50 Hz. They are not designed to autonomously plan motion toward distant goals, instead following detailed, real-time references from upstream sources. Most accept only the next-frame target, but three also process a short future trajectory, enabling smoother tracking by anticipating motion changes. This target motion preview, however, is only practical when future targets are available, making it unsuitable for real-time teleoperation, where human inputs arrive frame by frame.
Overall, these command interface choices largely reflect the type of demonstrations or upstream control each WBC is designed to support. Task-oriented demonstrations—such as moving objects or walking between waypoints—typically rely on low-dimensional inputs like root velocity and end-effector poses, while motion-capture mimicry requires high-dimensional whole-body targets to capture details. Although multi-modal interfaces are still in the minority, they are likely to become the norm as WBCs are deployed across a broader range of applications, where both simple and detailed controls are needed.
Finally, today’s WBCs offload all motion planning to the higher-level controller, even for seemingly common-sense actions like reaching for a nearby object. Looking forward, we may see WBCs evolve to handle sparser, less temporally dense goals, freeing higher-level reasoning layers (e.g. vision-language models) to focus on the semantic aspects of a task rather than micromanaging routine motions.
WBC Training Approaches
All of the WBCs in the inventory are trained entirely in simulation, with the resulting policies transferred to real hardware. While sim-to-real transfer involves its own set of tricks, such as domain randomization and external force disturbances, we’ll focus here on how the controllers are trained in simulation, since that’s where most of the design choices occur.
Why Reinforcement Learning?
Reinforcement learning (RL) is the backbone for training every WBC in the inventory because large-scale supervised data for low-level actions simply doesn’t exist. While humans can demonstrate motions, they can’t directly label the precise sequence of joint setpoints (the WBC outputs) required to achieve those motions, which would be necessary for supervised learning. However, we can evaluate a motion’s quality: if a controller attempts to follow a target command, we can measure how well the resulting motion matches the intent. Treating this as a reward signal naturally leads to RL, where the controller learns by trial and error to maximize reward across many simulated episodes.
Every WBC RL training pipeline shares a basic structure:
Episode Generation: Build a distribution over target motion commands, initial robot states, and terrain, then sample episodes where the robot must follow the specified command.
Reward Design: Define a reward function that encourages the robot to match the target commands while maintaining balance, smoothness, and energy efficiency.
Policy Optimization: Train the controller with an RL algorithm, almost always Proximal Policy Optimization (PPO) due to its stability and scalability.
We’ll go through each of these steps in turn.
Episode Generation
For 13 of the 14 loco-manipulation WBCs, episode generation leverages human motion capture datasets, which are retargeted to the desired robot body. Each episode samples a motion clip, initializes the robot at a random frame, and generates target commands derived from that clip. For example, a mocap clip of a person walking might yield a sequence of target root velocities or body keypoints for the WBC to track, depending on the chosen WBC command modality. The most commonly used dataset (9 WBCs) is AMASS, which contains 40 hours of motion data involving hundreds of subjects and 11000+ motions. The CMU Motion dataset is the next most commonly used (4 WBCs). In addition, a number of the WBCs supplement the existing datasets with their own mocap data and/or augmentations of the existing datasets.
In contrast, the four pure locomotion WBCs and one loco-manipulation WBC are trained without offline motion capture data. Instead, they sample randomized root velocity commands (e.g., forward speeds, turns, sidesteps) and rely on reward shaping to discover stable gaits that result in matching the velocity commands. Similarly, for loco-manipulation, randomized target end-effector positions can be sampled as training commands.
The majority of all of this training occurs on flat or near-flat ground for efficiency. However, at least 2 WBCs use a mix of procedurally generated terrains, e.g. ramps, stairs, uneven patches, to encourage terrain robustness..
The best recipe for balancing offline datasets and synthetic generation remains unclear. Large mocap datasets like AMASS offer diversity and realism, but often miss the task-specific motions and reactive behaviors needed for practical applications. In contrast, procedurally generated episodes or custom mocap can be crafted to densely cover a desired task space. Ultimately, designing the right training distribution may prove to be the single most critical factor in advancing WBC capabilities.
Reward Design
While details vary, most WBC reward functions balance three core components:
Tracking Accuracy: How closely the robot’s motion matches the target motion command. For example, if the target command modality is root velocity, then the reward will be maximized when the robot is moving at the correct velocity. Rather, if the target is full-body keypoint tracking, then the reward is maximized when the actual robot keypoints perfectly align with the target keypoints.
Stability and Balance: Penalizing falls, excessive tilts, or rapid angular velocities.
Smoothness and Efficiency: Discouraging jerky motions and excessive torque usage to promote natural, energy-efficient gaits.
Because bipedal locomotion is inherently cyclical and difficult to discover via pure exploration, 15 WBCs include explicit gait-shaping rewards, based on techniques from earlier locomotion work. For instance, a foot air-time reward encourages alternating foot contacts—ensuring one foot is planted while the other moves, but avoiding overly long stances.
Reward design remains one of the most time-consuming and ad hoc aspects of WBC training. These many-component reward functions require carefully tuned weights, yet the impact of each choice often only becomes clear after long, expensive RL runs. Outcomes are highly sensitive, and with few principled methods for setting these parameters, reward shaping often feels as much like art as science. Developing better tools and methodologies here could significantly improve the day-to-day workflow of WBC engineers.
Policy Optimization
All 18 WBCs use PPO (Proximal Policy Optimization) as the core RL algorithm. PPO’s popularity stems partly from its stability, scalability, and ease of parallelization, but also from historical momentum. Many labs already built expertise and infrastructure around PPO for legged locomotion. While other RL algorithms might match or exceed PPO’s performance, PPO remains the workhorse because it works reliably and isn’t yet the bottleneck in WBC development.
Beyond Pure RL: Teacher–Student Pipelines
While RL forms the foundation of every WBC training pipeline, 9 of the 18 controllers use a teacher–student framework to simplify learning and improve robustness. The process unfolds in two stages:
A teacher policy is trained first using RL, but with access to privileged information unavailable to the final controller (e.g. full world state estimates, ground-truth contact forces, or a future horizon of motion commands). The intent is for this information to make the RL problem substantially easier, particularly for behaviors involving complex contacts or rapid dynamics, where partial observations would otherwise slow or destabilize learning.
A student policy is then trained via supervised imitation to match the teacher’s actions, using only the restricted observations available at runtime. Most pipelines employ DAGGER (Dataset Aggregation)—rolling out the student in simulation, querying the teacher for the “correct” action at each state, and training the student to minimize its deviation from the teacher via a supervised loss (often mean-squared error).
Teacher-student pipelines offer clear advantages: they decompose the problem, letting RL focus on mastering behavior under idealized conditions, while the student handles sim-to-real constraints like limited sensing. However, this comes with extra complexity—both in engineering the teacher and tuning the distillation process. Notably, an equal number of WBCs succeed with pure RL alone, indicating that the best training pipeline is still highly task- and team-dependent. As WBCs are pushed toward greater generality and performance, curriculum design and hybrid pipelines like teacher–student approaches are likely to play a growing role.
Network Architectures
Compared to the elaborate, highly tuned designs common in fields like computer vision or language modeling, the network architectures used for WBCs remain relatively simple and small. Half of the controllers in the inventory (9 of 18) rely on a straightforward multilayer perceptron (MLP), mapping the robot’s state and motion commands directly to joint setpoints.
That said, several WBCs incorporate extensions to the basic MLP to address temporal context, input compression, or behavior diversity:
Variational Autoencoders (VAEs) (2 WBCs): Compress high-dimensional inputs (like joint states or keypoints) into a latent space before passing them to an MLP, regularizing learning and filtering noise.
Recurrent Layers (2 WBCs): LSTM-based memory layers provide implicit temporal context, reducing the need for long input histories and helping the controller implicitly infer dynamic state such as accelerations and momentum for smoother motion.
Mixture of Experts (2 WBCs): A small set of MLP “experts,” each specializing in different motion regimes (e.g., walking vs. standing), with a gating network selecting or blending outputs.
Transformers or Attention Layers (3 WBCs): Used to integrate temporal or multimodal inputs, enabling the controller to weigh past states or key features dynamically rather.
Despite these experiments, the field hasn’t converged on any deeply specialized or heavily engineered network designs for WBCs. Most remain relatively lightweight, prioritizing inference speed, robustness, and PPO training stability over architectural novelty. For now, it seems that factors such as training methodology (motion capture episodes, teacher–student pipelines, domain randomization) drive performance more than the network backbone itself. That said, as WBCs are pushed toward greater functionality and robustness, it’s likely that new architectures, beyond simple MLPs, will emerge as clearly beneficial and become preferred standards.
Final Thoughts
There you have it. Humanoid AI is still in its early days, but the shape of whole-body controllers is starting to emerge, with clear trends in their inputs, training, and architectures. Yet drawing firm conclusions about what “works best” remains difficult: every WBC depends on heavy tuning, trial and error, random seeds, and robot-specific adaptations. Current comparisons offer limited insight, often reflecting as much about implementation effort as about fundamental design. Truly understanding which choices matter and which are incidental will take time and collective experimentation. For now, real progress is more likely to come from careful ablation studies and systematic exploration within individual systems than from chasing state-of-the-art scores, gradually uncovering the principles that will shape the next generation of WBCs.
Looking ahead, a few big questions may shape where WBCs go next. How much should they “see” the world? Should they stay as pure stabilizers, or start handling basics like foot placement and collision avoidance so higher-level planners can focus on the big picture? Multi-modality and flexibility are also ripe for progress: imagine one controller that can smoothly switch between joystick-like navigation, full-body motion tracking, and even hitting simple long-horizon goals. That kind of capability will almost certainly push the field beyond today’s mostly MLP-based networks. And then there’s the data question: will huge mocap datasets like AMASS stay central, or can smartly crafted synthetic training data do the job just as well, or better? However it shakes out, the answers to these questions will define the next wave of humanoid control. I’ll be curious to see what’s changed when I circle back to this inventory in a year or two.